Why are there duplicate results?

Picking up from the last post, I'm now wondering why I'm getting multiple results in the UI when I search for phrases I know only exist on one page in the blog.
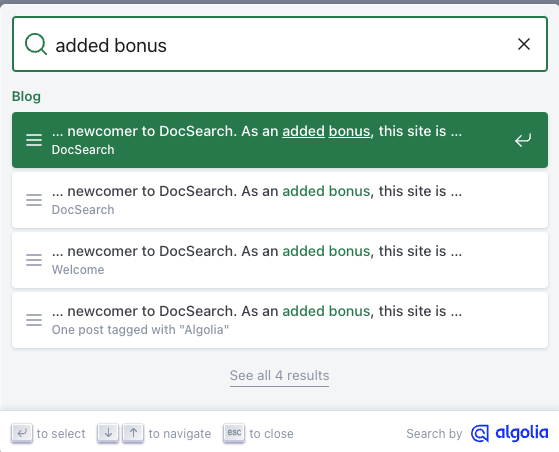
It turns out that is because there are actually four (4) different pages with that content:
- The blog page itself
- The blog landing page
- The tag page for Algolia
- The tag page for Docusaurus
When you run Build for Docusaurus, each of those pages are generated and thus, result in different search results. While technically correct I do not like this search experience. Instead, I want to see only one result, the actual blog page. Therefore, I'm thinking one of two things should happen:
- Remove the "extra" results from being returned
- Remove the "extra" records from being populated in my index to begin with
Since I can't see a reason to want those records in my index to begin with, I'd rather just have the entries for the blog pages themselves in the index. Therefore, I think what this will require is an update to the Crawler configuration file.
I see right away there are two properties to look at:
- discoveryPatterns
- pathsToMatch
After looking at those for a bit, what I really wanted was a way to exclude URLs. After a search on the Crawler docs, guess what, there is (https://www.algolia.com/doc/tools/crawler/apis/configuration/exclusion-patterns/#examples), so I added these to my crawler:
exclusionPatterns: [
"https://randombeeper.github.io/JamesDevDocsSrc/blog/tags/**",
"https://randombeeper.github.io/JamesDevDocsSrc/blog/",
],
Now my search results do not contain "duplicate" pages, only results that will go right to the blog post where the match is found.